
Programma
AI in Werving & Selectie
Hoe kan AI een goede en eerlijke arbeidsmarkt faciliteren - of frustreren? HR-technologie is niet neutraal. Hoe verbinden we de bestaande kennis uit de personeelspsychologie met de wereld van recruitment-algoritmes?
De inzet van zelflerende algoritmes bij werving & selectie heeft een zeer snelle vlucht genomen: op basis van CV screening, chatbots, gezichtsherkenning in videogesprekken, internetgedrag worden voorspellingen gedaan over de geschiktheid van kandidaten. Procedures lijken sneller en efficiënter. Maar hoe beïnvloedt het gebruik van AI de kansen op werk voor verschillende partijen? Wat zijn de gevolgen van AI voor de diversiteit op de arbeidsmarkt? Wat is de impact op werkzoekenden en organisaties?
HR-technologie is niet neutraal. Hoe kan AI een goede en eerlijke arbeidsmarkt faciliteren – of frustreren? Hoe maken we de werking van AI eerlijk en transparant? Hoe kunnen we ervoor zorgen dat het gebruik van algoritmes op een verantwoorde manier wordt ingezet? Om al deze vragen te adresseren zette de NSvP in 2019 de AI x Recruitment Challenge uit. Het leverde een kijkje ‘onder de motorkap’ van AI en inzichten in de werkelijke werking van algoritmes bij recruitmentbeslissingen. Drie initiatieven ontvingen subsidie van de NSvP. Hun bevindingen zijn hier te downloaden.
Uitkomsten van de AI-onderzoeken
De kracht van AI ten gunste van werkenden en werkzoekenden
Werkzoekenden in gesprek met algoritme over vacaturematching – over de mogelijkheid van wederkerigheid van AI in recruitment. Hoe kunnen mens en AI samen komen tot Responsible en Explainable AI? Een wetenschappelijk onderzoek in de praktijk door eelloo en Justus Liebig Universiteit.
Selectie met AI: meer of minder eerlijk dan traditionele selectie methoden?
Jacqueline van Breemen (onderzoeker en data analist bij NOA) vergeleek de uitkomsten door AI met die van traditionele selectiemethoden. Welke kandidaten hebben het meest winst van de toepassing van AI? En is selectie met gebruik van AI betrouwbaar?

Hoe ervaren sollicitanten de inzet van AI in selectieproces?
Een projectgroep aan de Vrije Universiteit onderzocht hoe het zit met de acceptatie van sollicitanten bij gebruik van AI in sollicitatieprocedures. Ze onderzochten de reacties op de selectieprocedure, de selectiebeslissing, en op de organisatie en de baan.
Is selectie met inzet van AI eerlijker en accurater?

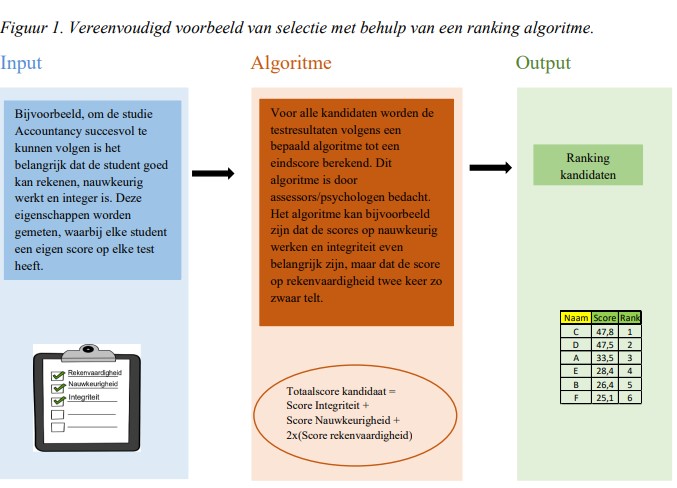
Je gaat solliciteren op een nieuwe baan en hoort dat er bij de selectie gebruik wordt gemaakt van artificial intelligence (kunstmatige intelligentie of AI). Wat betekent dat? Psychologisch advies- en onderzoeksbureau NOA deed onderzoek naar het gebruik van AI bij selectie. De uitkomsten werden vergeleken met die van traditionele selectiemethoden. Welke kandidaten hebben het meest winst van de toepassing van AI? En is selectie met gebruik van AI betrouwbaar? Het onderzoek van NOA werd binnen de AI x Recruitment Challenge medegefinancierd door de NSvP.
-
Bias #1: doelvariabale
De definitie van de doelvariabele bepalen wat er binnen de data mining gebeurt. Zij bepalen waarnaar gezocht wordt in de gegevens van sollicitanten. Verschillende keuzes kunnen systematisch een negatief effect hebben op bepaalde groepen.
-
Bias #2: trainingsdata
Wat een algoritme leert, hangt af van de ‘trainingsdata’ waaraan het is blootgesteld. De kwaliteit, waarde (en neutraliteit) van de ingevoerde data is hierbij essentieel. Bepaalde groepen mensen zijn over- of juist ondervertegenwoordigd, of worden zelfs over het hoofd gezien.
-
Bias #3: feature selection
Organisaties maken keuzes over welke indicatoren ze opnemen in hun algoritmische analyses. Dit wordt ‘feature selection’ genoemd. Bedrijven kiezen vaak voor kenmerken die voor het grijpen liggen, want informatie die veel gedetailleerder is – en daarmee kwalitatief beter – is moeilijker te verkrijgen én meestal erg duur.
-
Bias #4: proxies
Proxies zijn cijfers die correlaties aanduiden – blond haar is bijv. een proxy voor een blank huidtype. Aan de hand van zulke correlaties worden mensen door algoritmes ingedeeld in groepen. Criteria die mensen sorteren op baangeschiktheid, kunnen diezelfde mensen sorteren op groepslidmaatschap en zo tot discriminatie in het keuzeproces.
-
Bias #5: masking
Data mining kan traditionele vormen van opzettelijke discriminatie nieuw leven inblazen: beleidsmakers met vooroordelen kunnen namelijk hun intenties makkelijker maskeren. Eenvoudig gezegd, elke vorm van discriminatie die onopzettelijk gebeurt, kan net zo goed opzettelijk worden gedaan.
Waarom AI niet neutraal is: 5 mechanismen

AI’s Dirty Little Secret
Nieuwe technologie – met name AI – zorgt voor de groei van een enorme verborgen arbeidersklasse. Een heel leger van zelfstandige en geïsoleerde online werkers, die samen de drijvende kracht achter onze ‘slimme’ systemen vormen. We vergeten we vaak hoeveel mensenwerk er nodig is om AI systemen werkend te krijgen. Daarnaast gaat algoritmische inclusie over het in- of uitsluiten van minderheidsgroepen, en over aspecten van menselijk gedrag die worden uitgesloten door de nadruk op kwantificering en dataficering. Een stuk geschreven door Siri Beerends, SETUP.



